【python】定期代検索アプリ作ってみた!①駅名検索編

いいアイデア思いついた!
私: 電車の定期券って何回使えば元が取れるんだろう。
自分で計算してもいいけど、面倒なので自動化してみよう!
最終的にはこのサイトで使えるようにしたいです。
でも、やり方が分からない…
そういう時はAPIを使うニャ
API選定
今回必要なAPIの条件は次の4つです。
①経路検索できる
②定期代検索できる(必須)
③片道の代金が分かる
④無料(必須)
いろいろ検索しましたが、定期代検索できるかつ無料のAPIがなかなか見つかりませんでした。
そして、最終的にこのAPIを使うことに決定しました。
利用するためにRapidAPIのアカウント登録しました。
1か月500回までは無料だそうです。
RapidAPIは、APIのことを知らなくても直感的にAPIを使えるようになっているサービスです。
また、NAVITIME API 2.0 仕様書に詳しい使い方が書かれているので参考にしています。
全体像を確認
今回作るアプリケーションのイメージを説明します。
NAVITIME APIでは各駅にidが振られています。
ルート検索では駅名ではなくidを入力する必要があります。
なので、①駅名を入力→②idを検索→③idから経路検索→④経路から運賃を取得という方針で作ることにしました。
今回は①と②(ほぼ②)を作ろうと思います。
最終的にはDjangoと組み合わせてこのブログに組み込みますが、今回は一部分だけなのでGoogle colaboratoryを利用することにしました。
NAVITIME API使い方
先ほどのurlにアクセスした方ならお分かりだと思いますが、NAVITIMEJAPANのAPIは結構たくさん種類があってどれを使えばよいか分からなくなると思います。
今回、駅id検索で使うAPIは NAVITIME Transportです。
まず、上記のURLにアクセスしてください。
すると次のような画面となります。
右側の赤い○で囲った矢印をクリックして、画面を大きくしてください。
そして、左側のtransport_node/autocompleteを選択してください。
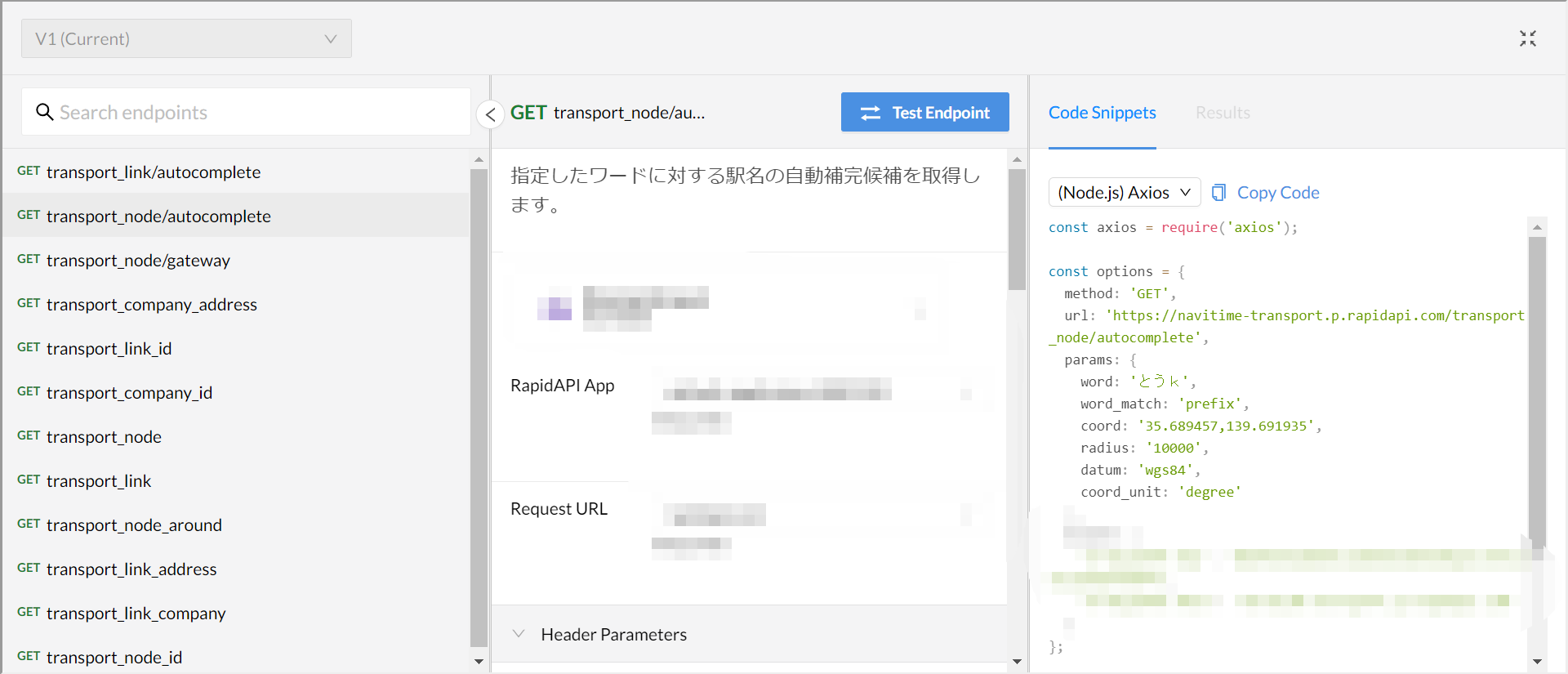
この画面でNode.jsと書いてあるプルダウンからPythonのRequestsを選択します。
画面の説明をします。
①画面中央はAPIのヘッダーやパラメーターを設定する画面です。
ヘッダーにはAPIキーなどのAPIにアクセスするのに必要な情報を記述します。
RapidAPIにログインしていれば自動的に入力されているはずなので、特にいじらなくて良いです。
パラメーターには、要求する情報を記述します。
今回はwordの欄に駅名を入力すればokです。
Optional Parametersは詳細な情報を入力します(必須ではないです)。
仕様書に細かい説明があるので、必要なら読んでおいてください。
私の場合はcoordとradiusの情報は必要がないので削除しました。
上側にあるTest Endpointをクリックすると実際にテストできます。
②画面の右側にはAPIを利用するためのコードが表示されます。
PythonのRequestsを選択しているので、Requestsライブラリを使用した場合のコードが表示されていると思います。
また、①で入力している情報が反映されているはずです。
これをコピペすればこれから作るアプリケーションに転用できます。
駅IDの取得
RapidAPIで取得したコードをベースに駅IDを取得するプログラムを組もうと思います。
出発駅と経由駅、到着駅の名前を入力して、IDを取得するというイメージで作成します。
なお、今回の実行環境はGoogle Colabolatoryとします。
まず、関数名はget_station_idとして、引数をstart、end、via_listとします。
経由駅は複数ある場合が考えられるので、リストを引数とします。
import requests def get_station_id(start, end, via_list):
RapidAPIで生成したコードをコピペします。
url = "https://navitime-transport.p.rapidapi.com/transport_node/autocomplete"
querystring = {"word":start,"word_match":"prefix","datum":"wgs84","coord_unit":"degree"}
headers = {
"X-RapidAPI-Key": #自分のAPIキー,
"X-RapidAPI-Host": "navitime-transport.p.rapidapi.com"
}
response = requests.get(url, headers=headers, params=querystring)このとき、print(response.json())は次のように出力されます。
#wordをとうkとした場合
{
"items": [
{
"id": "00019821",
"name": "東急歌舞伎町タワー〔新宿歌舞伎町〕",
"ruby": "とうきゅうかぶきちょうたわー",
"types": [
"highway_busstop",
"shuttle_busstop"
],
"address_name": "東京都新宿区歌舞伎町",
"address_code": "13104031000",
"coord": {
"lat": 35.69589,
"lon": 139.700351
}
},
{
"id": "00062656",
"name": "東京ガーデンテラス紀尾井町",
"ruby": "とうきょうがーでんてらすきおいちょう",
"types": [
"highway_busstop",
"shuttle_busstop"
],
"address_name": "東京都千代田区紀尾井町",
"address_code": "13101035000",
"coord": {
"lat": 35.680024,
"lon": 139.737255
}
},…#続きますこのように辞書形式で出力されます。
注目してほしいのは"items"のvalueに候補となる場所の辞書がリスト形式で格納されています。
つまり、"items": [{候補①の情報}, {候補②の情報}, …]という風に情報が並んでいることが分かると思います。
この中ですべての候補のidを取得しても仕方がないので、候補①のidだけを取得することにしました。
実際、正確に駅名を入力すれば候補は1通りになるはずです。
d = response.json()
start_id = d['items'][0]['id']まず、結果をd(dictionary)に格納します。
そして出発駅のidは'items'の0番目(候補①)の'id'にあるので、これをstart_idに格納します。
これで、出発駅のidを調べられました。
次は到着駅ですが、これは出発駅とほとんど同じです。
querystring = {"word":end,"word_match":"prefix","datum":"wgs84","coord_unit":"degree"}
response = requests.get(url, headers=headers, params=querystring)
d = response.json()
end_id = d['items'][0]['id']最後に経由駅です。
まず、経由駅のidを格納するリスト(via_id_list)を作ります。
そして経由駅がある場合はそのリストにidを追加して、ない場合は空のリストを返すようにしたいと思います。
経由駅が複数ある場合も考えられるので、for文で複数回idを取得するとよさそうです。
via_id_list = []
if len(via_list) != 0:
for station in via_list:
querystring = {"word":station,"word_match":"prefix","datum":"wgs84","coord_unit":"degree"}
response = requests.get(url, headers=headers, params=querystring)
d = response.json()
via_id = d['items'][0]['id']
via_id_list.append(via_id)
ここまででstart_id、end_id、via_id_listを取得することができたので、この3つをreturnで返したいと思います。
returnを使うと、戻り値はタプル形式となります。
最後にここまでのコードをすべてつなげたものを貼っておきます。
import requests
def get_station_id(start, end, via_list):
url = "https://navitime-transport.p.rapidapi.com/transport_node/autocomplete"
querystring = {"word":start,"word_match":"prefix","datum":"wgs84","coord_unit":"degree"}
headers = {
"X-RapidAPI-Key": #自分のAPIキー,
"X-RapidAPI-Host": "navitime-transport.p.rapidapi.com"
}
response = requests.get(url, headers=headers, params=querystring)
d = response.json()
start_id = d['items'][0]['id']
querystring = {"word":end,"word_match":"prefix","datum":"wgs84","coord_unit":"degree"}
response = requests.get(url, headers=headers, params=querystring)
d = response.json()
end_id = d['items'][0]['id']
via_id_list = []
if len(via_list) != 0:
for station in via_list:
querystring = {"word":station,"word_match":"prefix","datum":"wgs84","coord_unit":"degree"}
response = requests.get(url, headers=headers, params=querystring)
d = response.json()
via_id = d['items'][0]['id']
via_id_list.append(via_id)
return (start_id, end_id, via_id_list)
最後に
次回はルート検索編を投稿すると思いますので、楽しみに待っててください!
SNSで感想をシェアしてね↓